OpenMMLab实战营第二课 计算机视觉之图像分类算法基础
有点事 先简单写一下 晚上完善
传统方法: 设计图像特征(1990—2000)
人工设置特征 保留图像这种特征 以简化数据表达 从而可以计算分类 。
特征工程的天花板
在ImageNet 图像识别挑战赛里,2010 和2011
年的冠军队伍都使用了经典的视觉方法,基于手工设计的特征+
机器学习算法实现图像分类,Top-5 错误率在25% 上下。
传统的特征工程由于人工设置受限存在性能瓶颈。
于是有人提出了 利用机器直接学习提取用于分类的特征的方法
卷积实现一步特征提取👉 卷积神经网络
特征和图像一样具有二维空间结构
后层特征为空间邻域内前层特征的加权求和
多头注意力实现一步特征提取👉 Transformer
AlexNet 的诞生& 深度学习时代的开始
在2012 年的竞赛中,来自多伦多大学的团队首次使用深度学习方法,一举将错误率降低至15.3% ,而传统视觉算法的性能已经达到瓶颈,2015 年,卷积网络的性能超越人类。模型设计:设计适合图像的\(𝐹_Θ(𝑋)\)模型 例子如下
• 卷积神经网络
• 轻量化卷积神经网络
• 神经结构搜索
• Transformer模型学习:求解一组好的参数Θ
• 监督学习:基于标注数据学习
• 损失函数
• 随机梯度下降算法
• 视觉模型常用训练技巧
• 自监督学习:基于无标注的数据学习
卷积神经网络发展
AlexNet (2012)
Going Deeper (2012~2014)
VGG (2014)
残差网络ResNet (2015)
神经结构搜索Neural Architecture Search (2016+)
Vision Transformers (2020+)
ConvNeXt (2022)
轻量化卷积神经网络
GoogLeNet 使用不同大小的卷积核
基本思路:并不是所有特征都需要同样大的感受野,在同一层中混合使用不同尺寸的特征可以减少参数量
ResNet 使用1×1卷积压缩通道数
可分离卷积 将常规卷积分解为逐层卷积和逐点卷积,降低参数量和计算量
MobileNet V1/V2/V3 (2017~2019)
ResNeXt 将ResNet 的bottleneck block 中3×3
的卷积改为分组卷积,降低模型计算量
可分离卷积为分组卷积的特殊情形,组数=通道数
模型学习

目标:确定模型\(𝐹_\Theta\) 的具体形式后,找寻最优参数\(\Theta^\ast\) ,使得模型\(𝐹_{\Theta^\ast}(x)\) 给出准确的分类结果\(𝑃(𝑦|x)\)
监督学习
graph LR; 0[真值y]---1[损失L] A[图像]---B[模型$F_θ$] B---C[概率P] C---1
标注一个数据集\(\mathcal{D}=\left\{\left(X_i, y_i\right)\right\}_{i=1}^N\)
定义损失函数\(L:[0,1]^K \times \mathbb{N} \rightarrow \mathbb{R}\),衡量单个预测结果的"好/坏"
解一个最优化问题,寻找使得总损失最小的参数\(\Theta^\ast\)
\[ \Theta^*=\underset{\Theta}{\arg \min } \sum_{i=1}^N L\left(F_{\Theta}\left(X_i\right), y_i\right) \longrightarrow梯度下降法+针对视觉问题的技巧和策略 \]
优化参数用 随机梯度下降算法(SGD)
随机初始化参数\(Θ^{( 0)}\)
- 按照均与分布 或者高斯分布 \(W_{ij},b_i \sim U \left(-a,a \right)\) or \(W_{i j}, b_i \sim \mathcal{N}\left(0, \sigma^2\right)\)
- or Xavier 方法(2010):前传时维持激活值的方差,反传维持梯度的方差 没懂
- Kaiming 方法(2015):同上,但针对ReLU 激活函数 还是没懂orz
- 或者用训练好的模型参数(通常基于ImageNet 数据集) 替换预训练模型的分类头,进行微调训练(finetune)
随机选取数据子集ℬ,计算近似损失𝐿( Θ|ℬ)
前向+反向传播,计算梯度\(∇_Θ𝐿(Θ^{𝑡−1} |ℬ)\)
更新参数\(Θ ^{(𝑡)} = Θ^ {(𝑡−1)} − 𝜂∇_Θ𝐿(Θ ^{(𝑡−1)} |ℬ)\)
不断重复2-3知道收敛
学习率对训练的影响
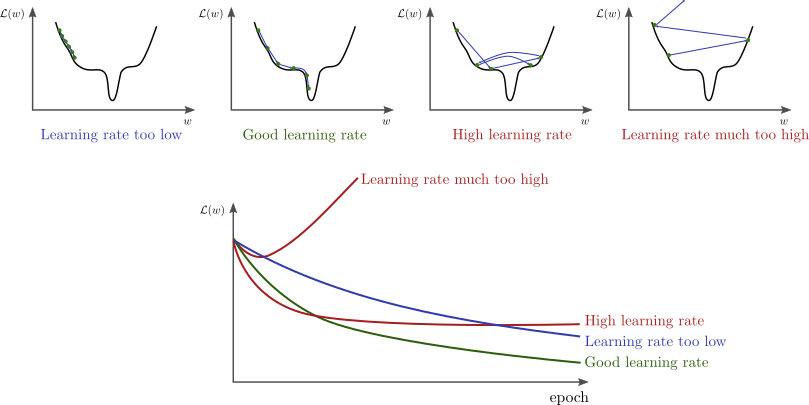
训练初期可使用较大的学习率(or
在训练前几轮学习率逐渐上升,直到预设的学习率,以稳定训练的初始阶段\(\eta_t=\frac{t}{T_0}𝜂_0(t\leq
T_0)\))损失函数稳定后下降学习率:
- 按步长下降
按比例下降\(\eta_t=𝜂_0𝑒^{−𝑘𝑡}\)
按倒数下降 \(\eta_t=\frac{𝜂_0}{\epsilon+t}\)
按余弦函数下降 \(\eta_t=\eta_{\min }^i+\frac{1}{2}\left(\eta_{\max }^i-\eta_{\min }^i\right)\left(1+\cos \left(\frac{T_{\mathrm{cur}}}{T_i} \pi\right)\right)\)
动量Momentum SGD
自适应梯度算法
正则化与权重衰减Weight Decay
数据增强Data Augmentation
训练泛化性好的模型,需要大量多样化的数据,
而数据的采集标注是有成本的
图像可以通过简单的变换产生一系列"副本",扩
充训练数据集
数据增强操作可以组合,生成变化更复杂的图像
- 几何变换
- 色彩变换
- 随机遮挡
组合数据增强AutoAugment & RandAugment
AutoAugment 借助强化学习,搜索数据增强的组合策略
RandAugment 更简单的搜索空间:随机选取N 个数据增强操作组合,幅度为M
Mixup 逐像素混合图像
CutMix 遮盖原图并用另一幅图填充
标签平滑Label Smoothing
动机:类别标注可能错误或不准确,让模型最大限度拟合标注类别可能会有碍于泛化性
做法:引入平滑参数𝜀,降低标签的"自信程度"
传统的one-hot 标签:\(P_i= \begin{cases}1, & i=y \\ 0, & i \neq y\end{cases}\)
平滑标签:\(P_i=\left\{\begin{array}{cl} 1-\varepsilon, & i=y \\ \frac{\varepsilon}{K-1}, & i \neq y \end{array}\right.\)
其中,𝐾 为类别总数
丢弃层Dropout
神经网络在训练时会出现共适应现象(co-adaption),神经元之间产生高度关联,导致过拟合
训练时随机丢弃一些连接,破坏神经元之间的关联,鼓励学习独立的特征
推理时使用全部连接
常用于全连接层,通常不与BN 混用
自监督学习
graph LR; B-.->B2 subgraph part 1 A3[由图像自身产生的标签y^ ]---3[$L^\prime$] A2[图像x]---B2[模型$F_θ$] B2---C2[特征z ] C2---D[辅助任务] D---3 end subgraph part 2 A[图像x]---B[模型$F_θ$] B---C[特征z ] C---D2[分类器] D2---1[损失L] 0[真值y]---1 end
标注数据是昂贵的 我们希望程序自己标注好
- 通过恰当设计辅助任务,让模型在无标注数据集 \(\mathcal{D}^\prime=\left\{X^\prime_i\right\}_{i=1}^N\)上学习好的特征
- 再把模型放在一个相对小的标注数据集上\(\mathcal{D}\) 训练分类(可选)
常见类型
- 基于代理任务 https://zhuanlan.zhihu.com/p/150224914
- 基于对比学习 arXiv:2006.09882, 2020.
- 基于掩码学习arXiv:2111.06377, 2021
Relative Location (ICCV 2015) 基本假设:模型只有很好地理解到图片内容,才能够预测图像块之间的关系
SimCLR (ICML 2020) 基本假设:如果模型能很好地提取图片内容的本质,那么无论图片经过什么样的数据增强操作,提取出来的特征都应该极为相似。
Masked autoencoders (MAE, CVPR 2022) 基本假设:模型只有理解图片内容、掌握图片的上下文信息,才能恢复出图片中被随机遮挡的内容。