OpenMMLab实战营第四课 目标检测算法基础
什么是目标检测
识别出大图片里的感兴趣部分 并且框出来
目标检测的应用
滑窗(Sliding Windows)
步骤
设定一个固定大小的窗口
遍历图像所有位置,所到之处用分类模型(假设已经训练好)识别窗口中的内容
为了检测不同大小、不同形状的物体,可以使用不同大小、长宽比的窗口扫描图片
缺点与改进思路
简单的滑窗需要很多窗口 计算成本太大
改进思路1:基于图像颜色或底层特征 使用启发式算法替换暴力遍历例(找出可能含有物体的区域)如R-CNN,Fast R-CNN 中使用Selective Search 产生提议框依赖外部算法,系统实现复杂,难以联合优化性能
改进思路2:减少冗余计算,使用卷积网络实现密集预测(用卷积一次性计算所有特征,再取出对应位置的特征完成分类)。
目前普遍采用的方式改进思路2
目标检测的基本范式
两阶段方法(基于区域的方法)R-CNN Fast R-CNN
以某种方式产生窗,再基于窗口内的特征进行预测
单阶段方法
在特征图上基于单点特征实现密集预测 YOLO SSD
其他方法
级联方法 Transformer方法
介绍了目标检测的技术演进
flowchart LR; subgraph A[传统方法] DPM end subgraph B[两阶段方法] 1[R-CNN] 2[Fast R-CNN] 3[Faster R-CNN] 4[RPN] 1-->2 2-->3 4-->3 3-->111( ) 111-->5[Mask R-CNN] end subgraph C[单阶段方法] 6[YOLO] 7[SSD] 88[YOLO v3] 89[YOLO v5] 90[FCOS] 91[YOLO X] RetinaNet end subgraph D[Transformer 方法] DETR Deformable DETR end subgraph F[级联方法] Cascade R-CNN end A--> B B--多尺度技术-->C C-->|特征金字塔Feature Pyramid Networks,FPN|B 111 --> F
基础知识
框,边界框(Bounding Box)
描述一个框需要4 个像素值:
• 方式1:左上右下边界坐标𝑙, 𝑡, 𝑟, 𝑏
• 方式2:中心坐标和框的长宽𝑥, 𝑦, 𝑤, ℎ
边界框通常指紧密包围感兴趣物体的框
检测任务要求为图中出现的每个物体预测一个边界框
框相关的概念
- 区域(Region):框的同义词
- 区域提议(Region Proposal,Proposal)
指算法预测的可能包含物体的框,某种识别能力不强的算法的初步预测结果 - 感兴趣区域(Region of Interest,RoI)
当我们谈论需要进一步检测这个框中是否有物体时,通常称框为感兴趣区域 - 锚框(Anchor Box,Anchor)
图中预设的一系列基准框,类似滑窗,一些检测算法会基于锚框预测边界框
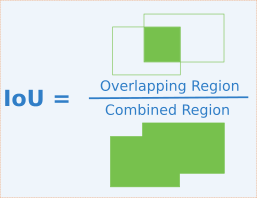
交并比(Intersection Over Union)
定义为两矩形框交集面积与并集面积之比,是矩形框重合程度的衡量指标
置信度(Confidence Score)
模型认可自身预测结果的程度,通常需要为每个框预测一个置信度
非极大值抑制(Non-Maximum Suppression)
滑窗类算法通常会在物体周围给出多个相近的检测框。这些框实际指向同一物体,只需要保留其中置信度最高的
通过非极大值抑制(NMS)算法实现:
输入:检测器产生的一系列检测框\(𝐵 =\left\{
𝐵_1, … , 𝐵_𝑛\right\}\) 及对应的置信度
\(𝑠 =\left\{ 𝑠_1, … , 𝑠_𝑛\right\}\)
,IoU 阈值𝑡(通常0.7)
步骤:
- 初始化结果集𝑅 = ∅
- 重复直至𝐵 为空集
① 找出𝐵 中置信度最大的框𝐵𝑖 并加入𝑅
② 从𝐵 中删除\(𝐵_𝑖\)以及与\(𝐵_𝑖\)交并比大于𝑡 的框
输出:结果集𝑅
边界框回归(Bounding Box Regression)
问题
滑窗(或其他方式产生的基准框)与物体精准边界通常有偏差
处理方法
让模型在预测物体类别同时预测边界框相对于滑窗的偏移量
graph LR; A[图像x]---B[卷积网络] B---C[特征] C---D[全连接层] C---D2[全连接层] D---F[c+1维分类概率] D2---F2[4维偏移量] F---分类损失 F2---回归损失
边界框编码Bbox Coding
边界框的绝对偏移量在数值上通常较大,不利于神经网络训练,通常需要对偏移量进行编码,作为回归模型的预测目标
两阶段算法概述
两阶段的检测范式最早由R-CNN 确立,因包含区域提议和区域识别两个阶段得名
经历一些列发展到Faster R-CNN 和Mask RCNN逐渐成熟
结合比较先进的主干网络和多尺度技术可以达到比较优越的检测精度,使用广泛
近几年(2020~)随着单阶段算法精度和速度的提高逐渐被取代
graph LR; A[输入图像]---|传统视觉算法|B[区域提议] B---C[裁剪缩放将提议框内的图像缩放至固定大小] C---D[分类] D---[汇总再NMS产生最终结果]
R-CNN(Region-based CNN 2013)缺点
慢:区域提议一般产生2000 个框,每个框都需要送入CNN 前传,推理一张图要几秒至几十秒 在裁剪提议框时进行了重复计算(物体重叠导致提议框重叠)
Fast R-CNN (2014)
对全图进行卷积网络产生了特征图 在裁剪提议框后找到对应的特征图在分类。
应为各个物体的提议框大小不一所以我们要在分类之前处理一下 使用RoI Pooling 和RoI Align
RoI Pooling
将不同尺寸的提议框处理成相同尺寸,使之可以送入后续的全连接层计算分类和回归
将提议框切分成固定数目的格子(上图中2×2,实际常用7×7,对齐ResNet等经典结构)
如果格子边界不在整数坐标,则膨胀至整数坐标
在每个格子内部池化,得到固定尺寸的输出特征图
RoI Align
图片出处:https://qiita.com/yu4u/items/5cbe9db166a5d72f9eb8
• 将提议区域切成固定数目的格子,例如7×7
• 在每个格子中,均匀选取若干采样点,如2×2=4 个
• 通过插值方法得到每个采样点处的精确特征
• 所有采样点做Pooling 得到输出结果
Faster R-CNN (2015)
增加了锚框Anchor的概念 以及从锚框到提议框的区域提议网络Region Proposal Network
锚框Anchor
在原图上设置不同尺寸的基准框,称为锚框,基于特征独立预测每个锚框中是否包含物体
① 可以生成不同尺寸的提议框
② 可以在同一位置生成多个提议框覆盖不同物体
多尺度方法
使用固定大小的卷积后的特征图预测不同尺度的物体效果比较差(特征图越小空间分辨率就越低预测小物体就会困难) 所以有应对不同尺度物体的方法
图像金字塔Image Pyramid
比较直觉的方法 把一张图片 缩放成不同大小图分别检测 就像使用不同度数的镜头看图会看到不同的物体。
优势:算法不经改动可以适应不同尺度的物体
劣势:计算成本成倍增加
层次化特征
基于主干网络自身产生的多级特征图产生预测结果
由于不同层的感受大小不同,因此不同层级的特征天然适用于检测不同尺寸的物体
优势:计算成本低
劣势:低层特征抽象级别不够,预测物体比较困难
特征金字塔网络Feature Pyramid Network (2016)
在层次化特征基础上
对低层特征用特征求和融入高层特征补充低层特征的语义信息
单阶段目标检测算法
One-Stage Detectors
正负样本不均衡问题
单阶段算法需要为每个位置的每个锚框预测一个类别,训练时需要为每个预测计算分类损失
图中锚框的数量远远大于真值框(数万vs
数个),大量锚框的预测真值为背景(负样本)
使用类别不平衡的数据训练出的分类器倾向给出背景预测,导致漏检
锚框vs 无锚框
基于锚框(Anchor-based)
• Faster R-CNN、YOLO v3 / v5、RetinaNet 都是基于锚框的检测算法
•
模型基于特征预测对应位置的锚框中是否有物体,以及精确位置相对于锚框的偏移量
•
需要手动设置锚框相关的超参数(如大小、长宽比、数量等),设置不当影响检测精度❌
无锚框(Anchor-free)
•
不依赖锚框,模型基于特征直接预测对应位置是否有物体,以及边界框的位置
• 边界框预测完全基于模型学习,不需要人工调整超参数✔️
• YOLO v1
是无锚框算法,但由于提出时间较早,相关技术并不完善,性能不如基于锚框的算法
目标检测模型的评估方法
正确结果(True Positive
TP):算法检测到了某类物体(Positive),图中也确实有这个物体,检测结果正确(True)
假阳性(False Positive
FP):算法检测到了某类物体(Positive),但图中其实没有这个物体,检测结果错误(False)
假阴性(False Negative
FN):算法没有检测到物体(Negative),但图中其实有某类物体,检测结果错误(False)
检测到的衡量标准:对于某个检测框,图中存在同类型的真值框且与之交并比大于阈值(通常取0.5)
准确率Precision 与召回率Recall
召回率recall =正确结果总数/真值框总数=#TP/#TP + #FN
准确率precision =正确结果总数/检测框总数=#TP/#TP + #FP
两种极端情况:
1.
检测器将所有锚框都判断为物体:召回率≈100%,但大量背景框预测为物体,FP很高,准确率很低
- 检测器只输出确信度最高的1个检测框:以很大概率检测正确,准确率=100%,但因为大量物体被预测
为背景,FN很高,召回率很低
一个完美的检测器应该有100%召回率和100%的精度;在算法能力有限的情况下,应该平衡二者
通常做法:将检测框按置信度排序, 仅输出置信度最高的若干个框
置信度= 分类概率,或修正后的分类概率(YOLO、FCOS)
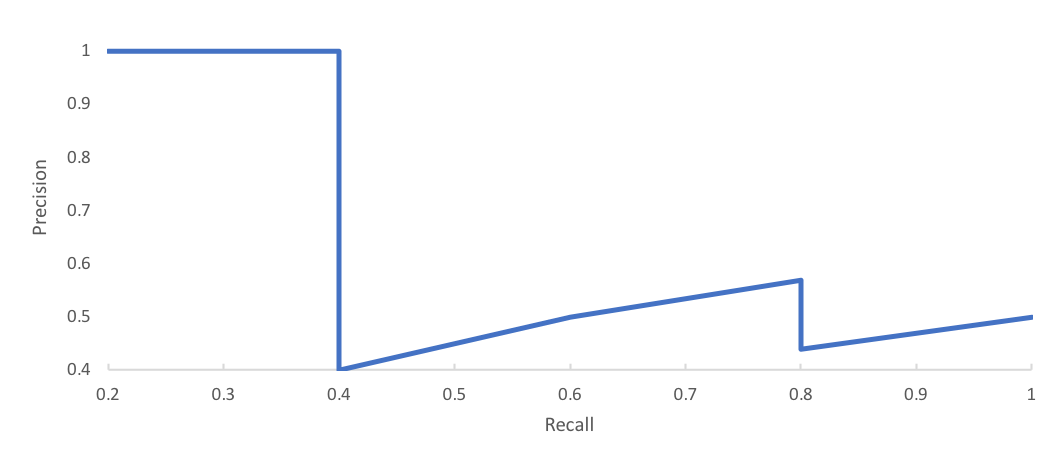
PR 曲线与AP 值
图片出处 https://www.jeremyjordan.me/evaluating-image-segmentation-models/
为得到阈值无关的评分,可以遍历阈值,并对Precision 和Recall 求平均
具体做法:
- 检测框按置信度排序,取前K 个框计算Precision 和
Recall - 遍历K 从1 至全部检测框,将得到的Precision 和
Recall 值绘制在坐标系上,得到PR 曲线 - 定义Average Precision = Precision 对Recall 的平均
值,即PR 曲线下的面积,作为检测器的性能衡量指标